import pandas as pd
pd.set_option('display.max_colwidth', None) # Set to display full-width dataframe Text Processing & Labelling [Part2]
Tutorials / Implementations
NLP
Sample of labelling data for Sentiment Analysis task
The full notebook is available here.
Labelling
df = pd.read_csv("preprocessed.csv")You can download the dataset here.
filtered_df = df[df.lang == "en"]Step 1: Segment Document into Sentences
We want to decrease the complexity when there are multiple sentences with different polarities in a doc. Therefore, instead of making prediction on a doc, we do for a sentence.
Note: This way also does not guarantee that we will not have a sentence with 2 conflict polarities. Yet, it reduces the proability of that situation.
def segment_review(df):
reviews = list(df["review"])
ratings = list(df["star_rating"])
new_reviews = []
new_ratings = []
for i in range(len(reviews)):
doc = nlp(reviews[i])
rating = ratings[i]
for sent in doc.sents:
new_reviews.append(str(sent))
new_ratings.append(rating)
return new_reviews, new_ratingsdoc_df = pd.DataFrame({"review": filtered_df["lower_case"], "star_rating": filtered_df["star_rating"]})# Check NaN
df["star_rating"].isnull().sum()0new_texts, new_ratings = segment_review(doc_df)segmented_df = pd.DataFrame({"review": new_texts, "star_rating": new_ratings})print("Number of data after segmenting:", len(segmented_df))Number of data after segmenting: 35448segmented_df.to_csv("segmented_df.csv", index=False)Step 2: Add labels using rating and pretrained-models’ predictions
label_df = segmented_df.copy(deep=True)Rating Label
def rating2label(rating):
if rating == 3:
return "Neutral"
elif rating < 3:
return "Negative"
else:
return "Positive"
def score2label(score):
if score == 1:
return "Positive"
else:
return "Negative"# Add rating labels
label_df["rating_label"] = label_df["star_rating"].apply(rating2label)BERT Label
%%capture
!pip install transformersfrom transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizer
def get_classifier(model_name, **kwargs):
id2label = kwargs.get("id2label")
if id2label:
model = AutoModelForSequenceClassification.from_pretrained(model_name, id2label=id2label)
else:
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
classifier = pipeline("text-classification", model=model, tokenizer=tokenizer)
return classifierModel 1: nlptown/bert-base-multilingual-uncased-sentimen
# Load pretrained model
model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
classifier = get_classifer(model_name)# Function to convert the model output to label
def get_prediction(text):
rating = int(classifier(text)[0]['label'].split()[0])
return rating2label(rating)label_df["nlptown_bert_label"] = label_df['review'].apply(get_prediction)label_df.head()label_df.to_csv("label_df.csv", index=False)get_prediction(label_df['review'][0])# Check number of neutral
label_df[label_df["nlptown_bert_label"] == "Neutral"][["review"]]Model 2: cardiffnlp/twitter-roberta-base-sentiment
from transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizer
model_name = "cardiffnlp/twitter-roberta-base-sentiment"
id2label = {0: "Negative", 1: "Neutral", 2: "Positive"}
classifier = get_classifier(model_name, id2label=id2label){'id2label': {0: 'Negative', 1: 'Neutral', 2: 'Positive'}}def get_prediction(text):
return classifier(text)[0]['label']label_df["twitter-robert_label"] = label_df['review'].apply(get_prediction)label_df.head()| review | star_rating | rating_label | nlptown_bert_label | twitter-robert_label | |
|---|---|---|---|---|---|
| 0 | i love my new laptop! | 5 | Positive | Positive | Positive |
| 1 | best computer i have ever own! | 5 | Positive | Positive | Positive |
| 2 | this computer forces me to be productive. | 5 | Positive | Positive | Positive |
| 3 | i used to wait around for this spinning wheel to stop, | 5 | Positive | Negative | Neutral |
| 4 | and now i can do everything so quickly | 5 | Positive | Positive | Positive |
label_df["review"] = label_df["review"].str.strip()label_df.to_csv("label_df_full.csv", index=False)Model 3: LSTM (Optional)
# Label by LSTM model
from allennlp.predictors.predictor import Predictor
predictor = Predictor.from_path("https://storage.googleapis.com/allennlp-public-models/basic_stanford_sentiment_treebank-2020.06.09.tar.gz")
lstm_label = list()
for i, review in enumerate(new_df['review']):
label = score2label(int(predictor.predict(review)['label']))
lstm_label.append(label)Plugin allennlp_models could not be loaded: No module named 'nltk.translate.meteor_score'label_df["LSTM_label"] = lstm_labelAnalyze labels and conflicts
%%capture
!python -m pip install -U matplotlib # The code requires to use the lastest version of matplotlib# Load labeled dataset
label_df = pd.read_csv("./label_df_full.csv")import seaborn as sns
def draw_bar_graph(data, title=None ,x_label=None, y_label=None):
sns.set_theme(style="white")
y_values = [float(v) for v in data.values()]
ax = sns.barplot(x=list(data.keys()), y=y_values)
ax.bar_label(ax.containers[0])
ax.set_ylim([0,max(y_values) + 2000])
ax.set_title(title, fontsize=16)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)conflict_rating_nlptown = label_df[~(label_df['rating_label'] == label_df['nlptown_bert_label'])]conflict_nlptown_roberta = list(label_df[~(label_df['twitter-robert_label'] == label_df['nlptown_bert_label'])]['review'])conflict_rating_roberta = list(label_df[~(label_df['twitter-robert_label'] == label_df['rating_label'])]['review'])conflicts = {"rating-roberta": len(conflict_rating_roberta), "rating-nlptown": len(conflict_rating_nlptown), "nlptown-roberta": len(conflict_nlptown_roberta)}draw_bar_graph(conflicts, title="Conflicts between labels", y_label="Number of samples")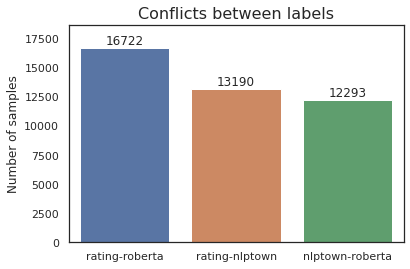
# Only count the samples has alphabet characters
non_neutral = conflict_rating_nlptown[conflict_rating_nlptown['nlptown_bert_label'] != "Neutral"]
character_exist = non_neutral[non_neutral['review'].str.lower().str.islower()]
len(character_exist)7344# Only count the samples has label as neutral and label conflict between nlptown_bert_label and twitter_robert_label
neutral = conflict_rating_nlptown[conflict_rating_nlptown['nlptown_bert_label'] == "Neutral"]
neutral_2_bert_conflict = neutral[neutral["nlptown_bert_label"] != neutral["twitter-robert_label"]]
len(neutral_2_bert_conflict)2348review = []
rating_label = []
nlptown_bert_label = []
twitter_robert_label = []
review += list(character_exist["review"]) + list(neutral_2_bert_conflict["review"])
rating_label += list(character_exist["rating_label"]) + list(neutral_2_bert_conflict["rating_label"])
nlptown_bert_label += list(character_exist["nlptown_bert_label"]) + list(neutral_2_bert_conflict["nlptown_bert_label"])
twitter_robert_label += list(character_exist["twitter-robert_label"]) + list(neutral_2_bert_conflict["twitter-robert_label"])conflict = {"review": review, "rating_label": rating_label, "nlptown_bert_label": nlptown_bert_label, "twitter-bert_label": twitter_robert_label}conflict_df = pd.DataFrame(conflict)conflict_df.head()| review | rating_label | nlptown_bert_label | twitter-bert_label | |
|---|---|---|---|---|
| 0 | i used to wait around for this spinning wheel to stop, | Positive | Negative | Neutral |
| 1 | ha ha. | Positive | Negative | Neutral |
| 2 | i do not have time to get coffee anymore. | Positive | Negative | Negative |
| 3 | i had an issue with my laptop. | Positive | Negative | Negative |
| 4 | the battery life drained fast | Positive | Negative | Negative |
conflict_df.to_csv("conflict_df.csv", index=False)print("Total numbers of samples we need to label is: ", len(conflict_df))Total numbers of samples we need to label is: 9692Label Rules
- Accept the label if the
rating_label,nlptown_bert_labelboth agree on the label. I don’t take in to account thetwitter-robert_labelin this situation since it is trained using tweets, not product review, which is not reliable compared to thenlptown_bert_label. Because of the human resource, it is not always to produce the perfect label for the dataset. Yet, the dataset sill can be improved later using Active Learning. - Accept the Neutral label if both
nlptown_bert_labelandtwitter-robert_labelboth agree on the label. The resonale for this is that when we do the sentence segmentation, some sentences from the positive/negative documents (labeled by star) have neutral sentiments, but still get labeled as positive or negative due to the rating_label. - Accept sample which review has alphabet characters. This rule will remove sample text such as “4.”, “!”, etc.
Distribution of labels in accepted data
accepted_df = label_df[label_df["rating_label"] == label_df["nlptown_bert_label"]]num_neutral = len(accepted_df[accepted_df["rating_label"] == "Neutral"])
num_positive = len(accepted_df[accepted_df["rating_label"] == "Positive"])
num_negative = len(accepted_df[accepted_df["rating_label"] == "Negative"])data = {"Negative": num_negative, "Neutral": num_neutral, "Positive": num_positive}
draw_bar_graph(data, title="Distribution of classes", x_label="Classes", y_label="Number of samples")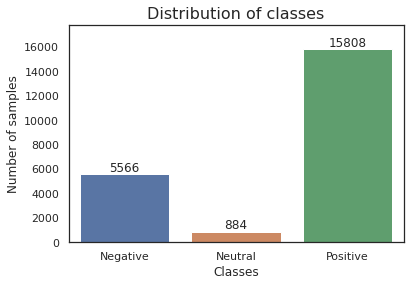
The dataset is unbalanced and the class has the least number of sample is Neutral, which is what we should expect. The reason is since we segment the doc to multiple sentences, there will be some sentences has neutral polarity but still get labeled as positive or negative due to the rating_label.
Upload to Lable Studio
def generate_import_json(text, labels):
json_instance = {}
json_instance['data'] = {"text": text}
json_instance['annotations'] = []
for label in labels:
json_instance['annotations'].append({
"result": [
{
"type": "choices",
"value": { "choices": [label] },
"to_name": "text",
"from_name": "sentiment"
}
]
})
return json_instancelabeled_df = df.drop(conflict_df.index)labeled_df.to_csv("labeled_df.csv", index=False)relabeled_df = pd.read_csv("relabeled_data.csv")relabeled_df[relabeled_df['annotation_id'] > 60000]| text | id | sentiment | annotator | annotation_id | |
|---|---|---|---|---|---|
| 0 | no es la mejor. | 521560 | Neutral | admin@slsops.gmail.com | 68106 |
| 4 | Ese es su único defecto, | 521559 | Neutral | admin@slsops.gmail.com | 68105 |
| 8 | 3 horas en trabajo medio, con varios aplicativ... | 521558 | Neutral | admin@slsops.gmail.com | 68104 |
| 12 | This machine is NOT a touchscreen. | 521465 | Negative | admin@slsops.gmail.com | 68011 |
| 16 | Also when I try to use my audio interface in L... | 521453 | Neutral | admin@slsops.gmail.com | 67999 |
| ... | ... | ... | ... | ... | ... |
| 672 | Like: size, weight, screen picture, battery us... | 521395 | Positive | admin@slsops.gmail.com | 67941 |
| 676 | Almost too perfect. | 521394 | Positive | admin@slsops.gmail.com | 67940 |
| 680 | I don’t have time to get coffee anymore. | 521393 | Negative | admin@slsops.gmail.com | 67939 |
| 684 | Ha ha. | 521392 | Positive | admin@slsops.gmail.com | 67937 |
| 688 | I used to wait around for this spinning wheel ... | 521391 | Positive | admin@slsops.gmail.com | 67936 |
173 rows × 5 columns
samples = []
rating_label = list(conflict_df['rating_label'])
LSTM_label = list(conflict_df['LSTM_label'])
distilbert_label = list(conflict_df['distilbert_label'])
conflict_text = list(conflict_df['text'])
for i in range(len(conflict_df)):
samples.append(generate_import_json(conflict_text[i], [rating_label[i], LSTM_label[i], distilbert_label[i]]))import requests
def upload_2_labelstudio(samples, project_num):
headers = {'Content-Type': 'application/json', 'Authorization': 'Token 05f1e1540050e570826c2f6229b4a0a20bde2d1f'}
url = f'https://label.slsops.athenka.com/api/projects/{project_num}/import'
r = requests.post(url, headers=headers, data=samples)
print(r.text)import json
for i in range(0, len(conflict_df), 500):
json_data = json.dumps(samples[i:i+500])
upload_2_labelstudio(json_data, 274)sample_json = [
{
"data": { "text": "This is a test sentence" },
"annotations": [
{
"result": [
{
"type": "choices",
"value": { "choices": ["Negative"] },
"to_name": "text",
"from_name": "sentiment"
}
]
},
{
"result": [
{
"type": "choices",
"value": { "choices": ["Neutral"] },
"to_name": "text",
"from_name": "sentiment"
}
]
},
{
"result": [
{
"type": "choices",
"value": { "choices": ["Positive"] },
"to_name": "text",
"from_name": "sentiment"
}
]
}
]
}
]